

视频中包含丰富的多模态信息,有利于字幕生成 [80]。具体来说,除了视频本身,还有一些有用的文本 (例如,视频标题、描述和字幕)和图像(例如,单独 的视频帧)。基于这一观察,我们提出使用几个具有不 同模态输入的字幕生成模型。我们从包含31个字幕生成模型的大型池开始。模 型池的介绍在附录 B.1 中。由于在70M视频片段上运行所有模型的推断是计算密集的,我们根据用户研究 构建了一个性能良好的八个模型的简短列表。该列表 显示在图 3 的y轴上。有关此过程的更多细节在附录 B.3 中。简而言之,这些模型由五个具有不同预训练 权重和输入信息的基础模型组成。这五个基础模型 包括 Video-LLaMA [88](视频VQA)、VideoChat(视频VQA)、VideoChat Text(将视频内容文本化 的自然语言模型)、BLIP-2(图像字幕生成)和 MiniGPT-4(图像VQA)。为了通过跨模态教师模 型实现视频字幕生成,我们针对每种模态制定了不同 的字幕生成过程。例如,对于VQA模型,除了视觉数 据,我们还输入一个包含额外文本信息的提示,并要 求模型将所有多模态输入总结为一句话。 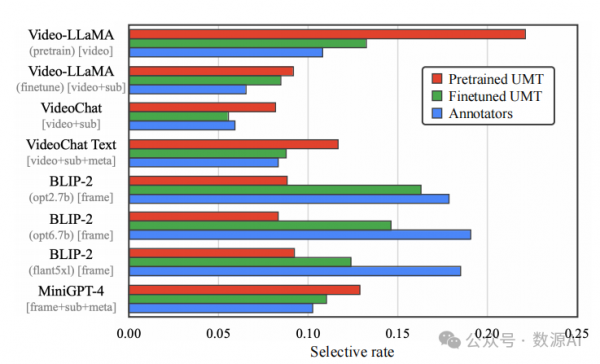

我们假设使用不同模态数据的教师模型在不同类 型的视频上表现良好。例如,由于具有处理时间信息 的额外模块,视频模型可以在具有复杂动态的视频上 表现更好。另一方面,由于它们是使用大规模图像-文 本配对数据集进行训练的,图像模型可以准确地为具 有罕见和不常见对象的视频生成字幕。最后,对 于视觉难以理解的视频,VQA模型具有优势,因为它 们可以利用额外的文本线索。
这一假设可以通过数值评估得到支持。具体来说, 我们进行了一个用户研究,要求参与者从八个候选项 中选择最佳字幕。我们在图 3 中绘制了每个教师模型 的选择率(蓝色柱形图)。结果显示,最佳字幕由不同 的教师模型生成。此外,单个教师模型的最高选择率 (即,BLIP-2 with opt6.7b [90])仅为17.85%。这一事实 表明单个模型在各种视频上的字幕生成能力有限。
3
Fine-grained Video-to-Text Retrieval
给定一个视频的多个候选字幕,我们寻找与视频 内容最匹配的字幕。一个直观的想法是使用现有的通 用视频到文本检索模型来选择这样一个字幕。不幸的是,我们发现它们通常无法选择最佳结果。一 个原因是通用模型是使用对比学习目标 进行训练的,并学会区分一个样本与其他完全不相关的样本1。相比之下,在我们的情况下,所有候选字幕与视频样本高度相关,并要求模型在每个字幕中识别微小差异以实现最佳性能。
为了将检索模型定制到我们的“细粒度”检索场 景,我们收集了一个包含 100K 个视频的子集,其中人类注释员选择包含有关视频主要内容最正确和详细 信息的字幕。然后我们在这个数据集上对 Unmasked Teacher(UMT) 进行微调。我们对对比损失实施了硬负采样,其中注释员未选择的七个字幕组成 了硬负样本,并被分配了更大的训练权重。
我们在验证集上定量评估了 UMT 在进行微调和未 进行微调时的检索性能。实验表明,经过微调的 UMT 可以达到 35.90% 的 R@1 准确率,明显优于预训练的 UMT,其 R@1 为 21.82%。值得注意的是,我们进行 了人类一致性评估,要求另外两个人重新执行注释, 并将结果与原始注释进行比较。平均人类一致性得分 仅为 44.9% 的 R@1,表明当有多个同样优秀的字幕时, 任务是主观的。或者,如果我们将三个人中任何一个 选择的字幕视为好的字幕(即,一个视频可能有多个 好的字幕),UMT 可以达到 78.9% 的 R@1。此外,在 图 3 中,我们展示了经过微调的 UMT(绿色柱)可以 选择与人类选择的字幕分布类似的字幕(蓝色柱)。
4
Fine-grained Video-to-Text Retrieval
尽管上述字幕生成流程可以生成有希望的字幕, 但庞大的计算需求阻碍了其扩展数据集规模的能力。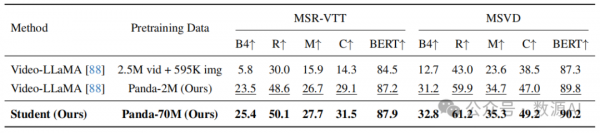
Zero-shot video captioning (%)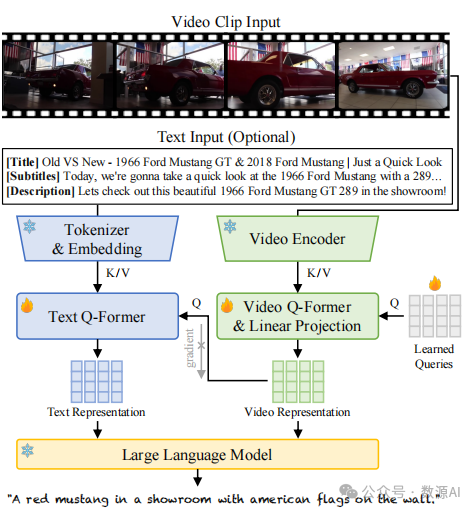
Architecture of student captioning model
事实上,需要运行 8 + 1 个不同的模型来注释单个视频片段。为了解决这个问题,我们在 Panda-70M 上学习了一个学生字幕模型,以从多个教师模型中提炼知识。
如图 4 所示,学生模型包括视觉和文本分支,利 用多模态输入。对于视觉分支,我们使用与 VideoLLaMA 相同的架构来提取与 LLM 兼容的视频表示。对于文本分支,一个直接的设计是将文本嵌入直接输入到 LLM 中。然而,这将导致两个问题:首先, 视频描述和字幕的文本提示可能过长,主导了 LLM 的 决策并且增加了沉重的计算负担;其次,描述和字幕 中的信息通常是嘈杂的,且与视频内容不必对齐。为了解决这个问题,我们添加了一个文本 Q-former 来提取具有固定长度的文本表示,并更好地连接视频和文本表示。Q-former 的架构与 BLIP-2 中的 Query Transformer 相同。在训练过程中,我们阻止文本分支到 视觉分支的梯度传播,并仅基于视频输入训练视觉编 码器。有关学生模型的架构和训练的更多细节请参见附录 D。
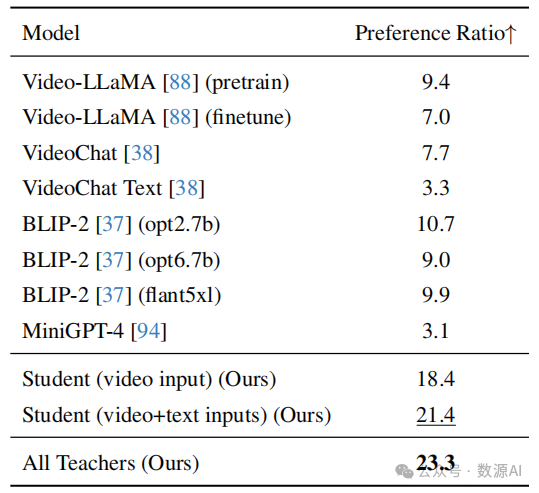 Comparison of the teacher(s) and student captioning models (%)
Comparison of the teacher(s) and student captioning models (%)
实验与结果
我们在附录 E 中展示了 Panda-70M 的样本。为了 定量评估 Panda-70M 的有效性,我们在三个下游应用 中测试了其预训练性能:视频字幕生成(视频字幕生成)在第 4.1 节,视频和文本检索(视频和文本检索) 在第 4.2 节,视频生成(视频生成)在第 4.3 节。下游模型的训练细节遵循官方代码库,除非另有明确说明。
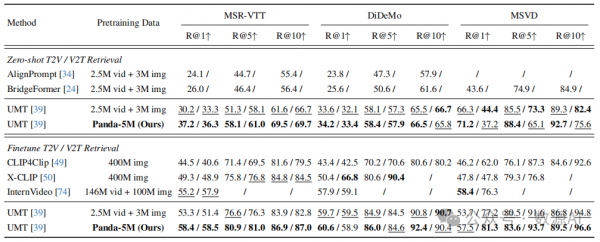
Video and text retrieval (%)
Qualitative comparison of video captioning

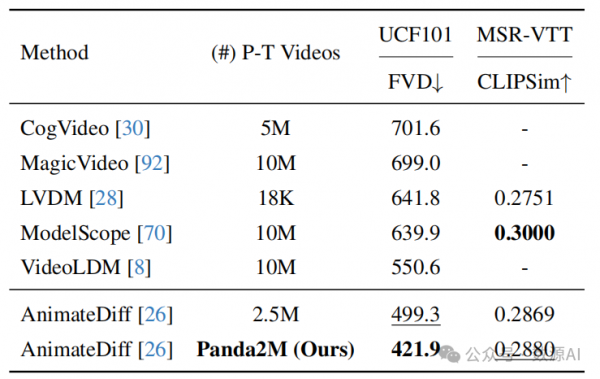
Zero-shot text-to-video generation
Qualitative results of text-to-video generation