

随着计算机视觉和自然语言处理的发展,有越来越多的研究人员把目光转向于如何结合多种模态的信息完成更现实且更具有挑战性的任务。本次Fudan DISC实验室将分享EMNLP2020和ICLR 2021中关于多模态机器学习的的3篇论文,介绍了近期涌现出的多模态领域的新任务和新思路。

来自:复旦DISC
用于弱监督短语定位的多模态对齐框架
MAF: Multimodal Alignment framework for Weakly-Supervised Phrase Grounding
论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.159.pdf
代码地址:
https://github.com/qinzzz/Multimodal-Alignment-framework
该篇文章关注于弱监督的phrase grounding,研究如何通过弱监督的方式将文本短语与图像区域对应起来。提出了一种多模态对齐框架,利用细粒度的视觉特征和视觉感知的文本特征来建模短语-物体的相关性。
通过检测跨模态不一致性以防范自动生成的虚假新闻
Detecting Cross-Modal Inconsistency to Defend Against Neural Fake News
论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.163.pdf
代码地址:
https://github.com/rxtan2/DIDAN
该篇文章关注于多模态虚假新闻检测,提出了一个多模态的虚假新闻检测任务和相应的数据集NeuralNews,并提出了一种通过跨模态不一致性来帮助模型做出更准确的判断。
在文本、表格和图像上的复杂问答
MultiModalQA: Complex Question Answering Over Text, Tables and Images
论文地址:
https://openreview.net/forum?id=ee6W5UgQLa
代码地址:
https://allenai.github.io/multimodalqa
该文章关注于多模态问题,提出了一个全新的数据集,其中包含了需要综合利用图像、文本、表格进行跨模态推理才能完成的问题。此外也提出了一种新的跨模态QA模型,在推理过程中隐式地对多模态问题完成分解。
1

论文动机
Phase grounding研究的是如何把文本短语和图像上的某个区域对应起来。例如''A young boy crawls across the wood floor towards the water bottle''。那么给定一个图像和短语描述,要求模型能够正确定位到符合描述的男孩(如图被蓝色框框中)。

如下表所示,现在常用的phrase grounding数据集以下几种:①从COCO数据集构建的RefCOCO, RefCOCO+, RefCOCOg;② 还有从Flick 30k中构建的Flickr 30k entities。
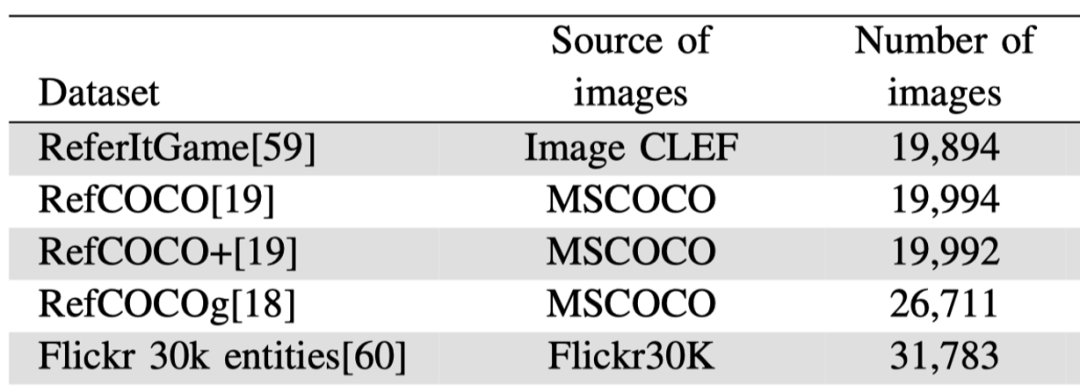
但是由于获得短语和图像区域对齐的标注比较困难,所以当前的phrase grounding数据集都比较小,限制了该任务的发展。举例来说,这些有标注的数据集通常都只有30k+的图像数量,但是其他有图像-和图像描述对应关系的数据集,如COCO,却有300k+的图像数量。
所以相比于利用phrase和object之间的标注信息,有一些人提出能否通过图像-和图像标注这种弱监督信号,来完成phrase grounding。这种便是弱监督的phrase grounding方法,主要有以下三种思路:① 通过重建phrase来学习图像和文本两种模态间的关系;② 有些工作更进一步,通过引入外部知识,来同时重建短语和图像区域;③ faster-rcnn检测得到的物体的label,提供了丰富的语义信息,可以用来对齐短语和图像区域,即通过减小图像区域和短语空间上的不一致性来对模型进行优化。然而在该方法存在缺点,即有很多不同的物体但是实际上他们的label都是一样的,这就会造成歧义。
如上图所示,图中有一个年长的人,还有一个背着红色东西的人。那么仅用''man''这样的label是不足以区分他们的。因此本文提出,可以利用一些更为细粒度的图像特征,来帮助区分物体。
方法
本文对于短语定位(phrase grounding)任务的建模参考了之前的工作,把该任务看做是一个ranking的问题,计算图中检测到的每个物体的视觉特征和文本特征的相似度分数,然后选择相似度最高的那个物体作为短语定位的结果。本文利用细粒度的视觉特征和文本特征来建模短语-物体的相关性,基于对比学习(Contrastive Learning)对模型进行优化。模型的整体框架如下图所示。
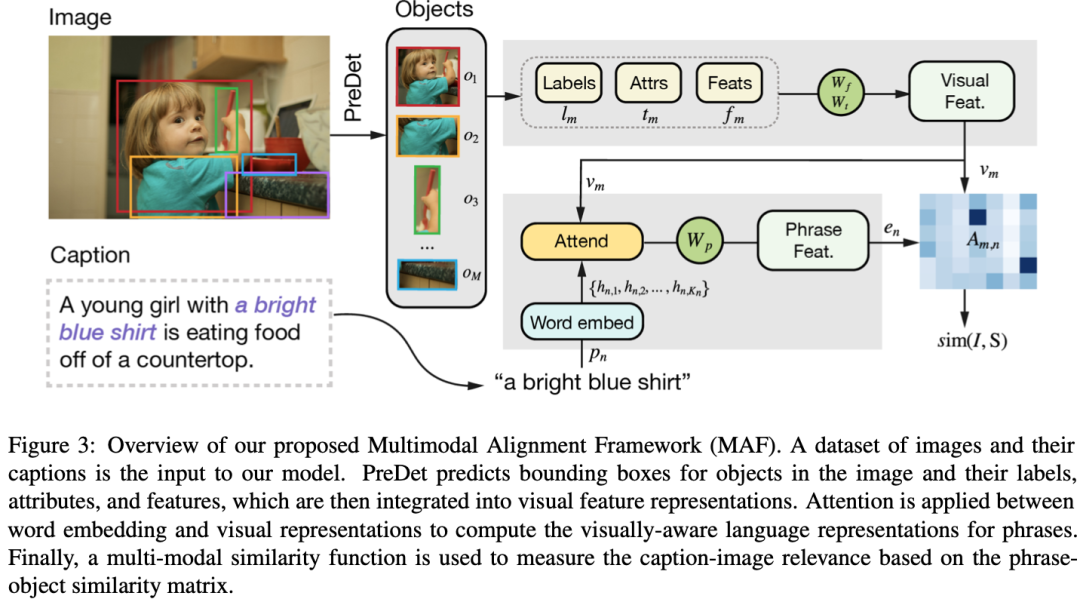
1. 细粒度的视觉特征和文本特征
视觉特征.之前的工作仅利用了通过目标检测器得到一种特定输出作为视觉特征表示(VFR),如仅仅利用了物体特征或者仅仅利用预测的标签嵌入作为视觉特征表示VFR。但是这种单一的VFR尝尝缺少部分信息。因此本文提出同时利用每个物体从目标检测器中提取的不同方面特征。特别地,本文通过Faster-RCNN可以得到每个物体的三种信息,分别是物体的标签嵌入 ,物体的属性 ,以及物体的视觉特征 。通过Glove词向量,可以得到把标签和属性从文本转成词嵌入,然后把物体的这三种特征融合起来,得到新的物体的视觉特征 :
其中m代表图像中的第m个物体。
文本特征.对于图像标注(caption),本文将标注分解为n个短语。通过Glove来获得短语的特征。然后利用视觉特征来对每个短语特征进行attention,然后根据注意力权重加权求和得到短语的特征表示 。
2. 多模态相似度计算
最后进行文本和图像的相似度计算,sim(I, S)表示图像I和句子S的相似度,计算方式如下:
其中A是短语和物体的相似度矩阵,它通过短语特征 和物体特征 点乘得到,代表了第n个短语和所有物体之间的相似度。 代表了使用最高的得分代表短语n和图像的相似度分数。然后求平均得到整个文本和图像的相似度。
3. 对比学习训练
本文训练阶段采用了对比学习的方法,将匹配的图像和标注作为正样本,不匹配的图像-标注对作为负样本,目标是使得正样本的匹配分数大于负样本。
实验
实验设定
数据集采用了Filckr30k Entities。评价指标采用top-1准确率,如果预测出的bounding box和ground-truth的iou>0.5,那么就把这个预测当做是正确的。
实验结果
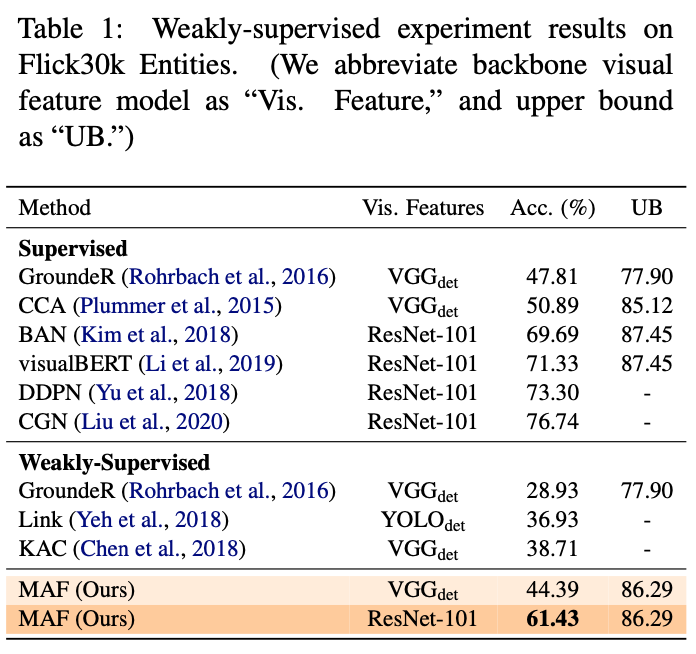
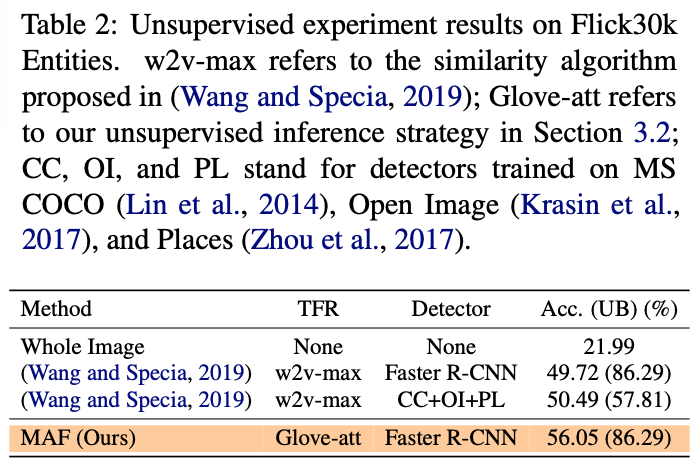
本文分别在弱监督和无监督设定下进行了实验,实验结果分别如下图所示。在弱监督的设置下,使用VGG作为backone特征,本文模型相比于之前的SOTA模型有6个点左右的提升,在使用ResNet-101作为backone特征后,进一步提升16个点;在无监督的设定下,相比于SOTA有5个点左右的提升。实验结果体现出了本文模型的有效性。
2

论文动机
生成式模型近年来的发展十分迅速,在CV和NLP领域都表现出了非常优越的性能,可以生成一些以假乱真的图像,还有故事、新闻等等。然而这些技术也被应用到了虚假新闻的生成上,对这些技术的恶意使用可能会带来重大的社会问题。近期也有一些工作对虚假新闻检测进行了尝试。但是目前的方法都存在明显的局限性,即大都只是对文本的虚假新闻进行了检测。
因此本文主要从以下三个方面对虚假新闻检测进行了改进:
提出一种了多模态的虚假新闻检测任务。不仅利用新闻的文本内容对虚假新闻进行检测,还同时对新闻中包含的图像-标注进行检测。
为此,本文提出了一个新的数据集---NeuralNews数据集,它同时包含了人类和机器生成的新闻,人类生成的新闻来自goodnews数据集,虚假新闻由GROVER模型自动生成。
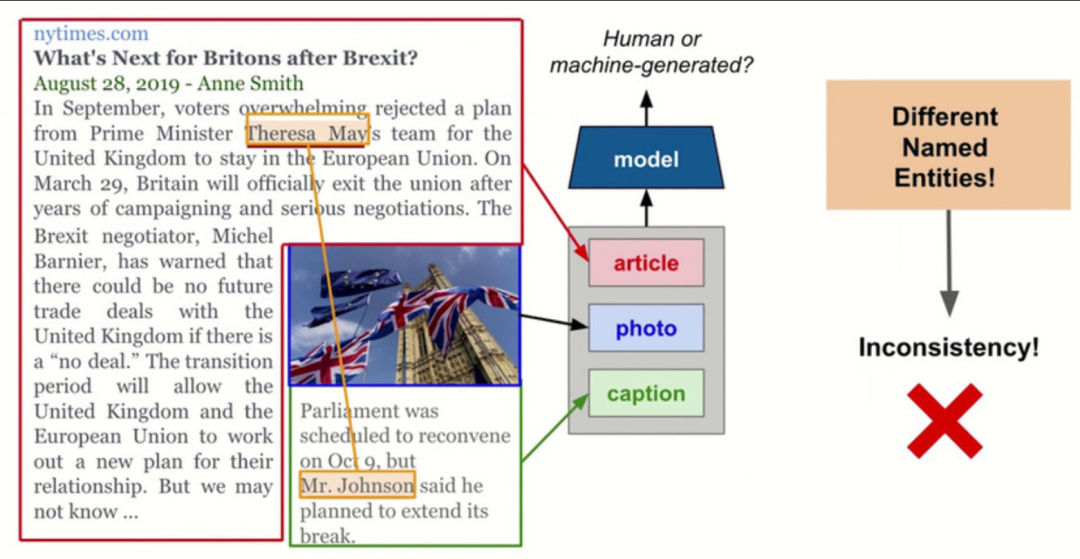
此外,本文提出了一个基于命名实体的基线模型(baseline),利用新闻内容和图像或者标注之间可能存在的语义不一致来检测虚假新闻。如下图所示,新闻中提到的人是"Theresa",但是图像标注中又变成了Johson。所以便可以根据这种细粒度的信息来帮助判断一个新闻是否是由机器生成的。

数据集
下图中展示了本文提出的数据集的统计情况,数据集中包含四种类型的新闻,分别是:
真实的article+真实的caption
真实的article+机器生成的caption
生成的article+真实的caption
生成的article+生成的caption
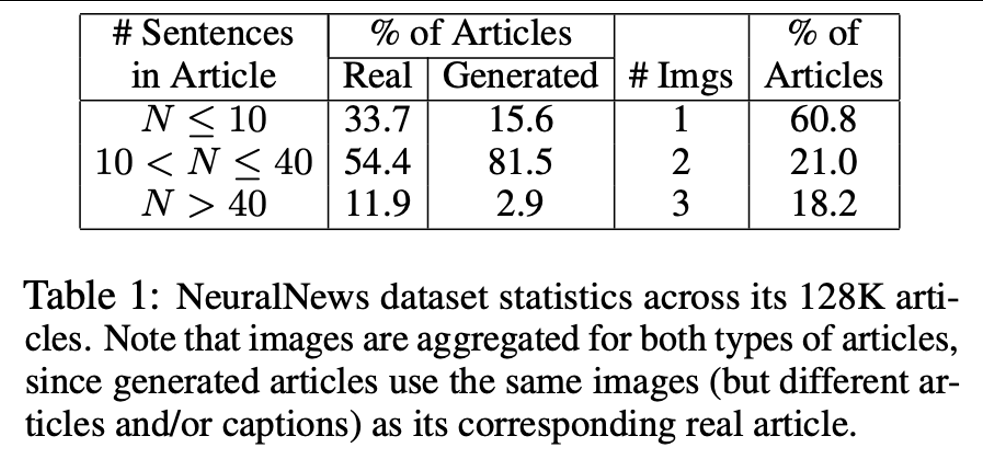
真实的是指人类编写的新闻。每种类型的文章(article)收集了大约32k个样本,总共约有128个样本。大多数新闻的文本部分最多包含40个句子,此外,尽管大多数新闻只包含一个图像和图像标题,但仍然有18.2%的新闻有3个图像。本文认为这样的设置将更具有挑战性,而且便于探究不同图像数量给模型带来的影响。下图展示了数据集的统计分析:
方法
如下图所示,本文利用了文章(article),图像(photo)和图像标注(caption)中可能出现的命名实体的不一致这一种细粒度的线索,来帮助进行假新闻检测。通常来说,人很少会犯这种错,但是通常机器或者现在的生成模型其实很容易犯生成的内容前后不一致的这种错误。因此可以利用这一细粒度的不一致特性来对真实和机器生成的新闻进行判断。
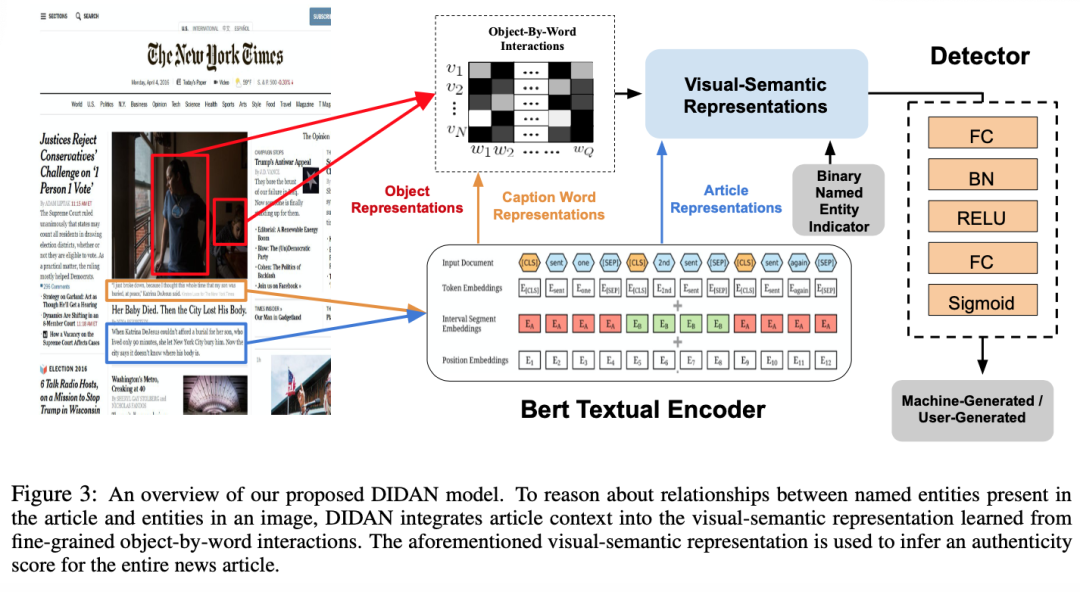
下图中展示了本文模型的概述,大概可以分为5步:① 首先使用BERT来对图像标注(caption)和文章(article)进行编码;② 然后提取图像中物体的特征,并利用图像标注的特征对图像物体特征进行attention,计算注意力权重。根据注意力权重对物体的视觉特征加权求和,得到最终的几个物体的特征。③ 将物体的视觉特征和文章特征进行结合,得到visual-semantic特征表示。④ 本文进一步提出了二元命名实体指示器(binary named entity indicator),用来检测是否文章中包含了在图像标注中出现的命名实体。这种操作类似于引入了一种一阶逻辑,来对模型进行正则化。举例来说,如果文章和图像标注当中没有出现同一个命名实体,那么可以推出这是个假新闻。⑤ 最后利用visual-semantic特征和上述指示特征拼接,进行融合。输入到一个浅层的MLP中进行最终的预测,判断这个新闻是人写的还是机器生成的。
实验结果
定量结果
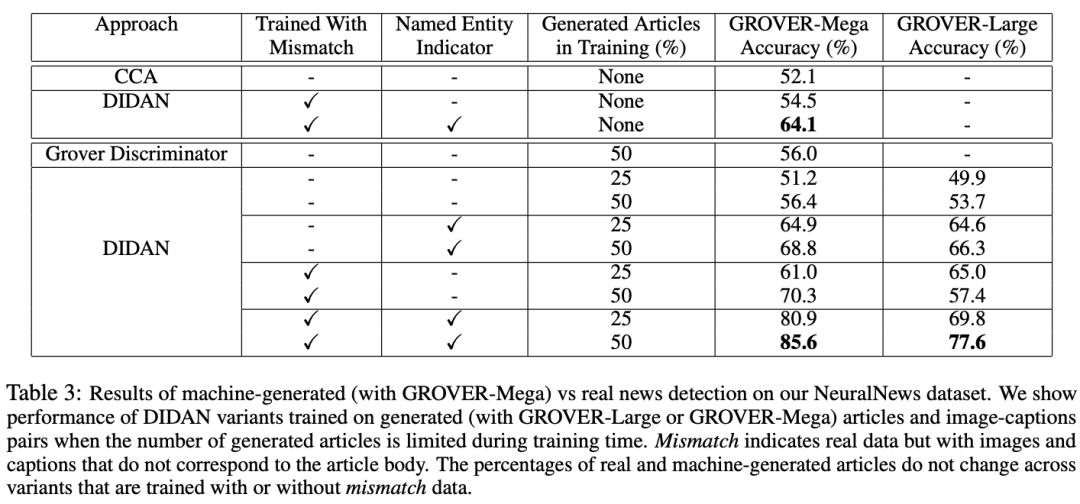
本文的定量实验结果如下表所示,整体来看本文模型相比于其他模型(如CCA模型)显著提高了准确率,这体现出了本文模型的有效性。此外,本文还进行了一些消融实验,来探究模型中部件的有效性。如下表中展示了命名实体指示器以及利用负样本进行训练的作用。引入了命名实体指示器(NEI)的模型在面对更具有挑战性的假新闻时取得了巨大的改进与提升。
定性结果
本文展示了本文模型对样例的预测结果示例,下图展示了一个模型做出正确预测的样例,可以看到图像标注和文章中所提及的人物不匹配,本文模型DIDAN可以很好的识别到这种细粒度的线索,并且据此做出准确的预测。
下图展示了一个对本文模型DIDAN非常有挑战性的例子。在这个例子中,图像标注仅仅和文章是相关的,但是图像和文章中描述的内容却不是很相关。此时本文模型做出了错误的预测,如果要能够成功地对这种相关性做出判断,需要更为抽象的推理能力,这指出了一个未来可以继续改进的方向。

3

论文动机
当人们要回答一个复杂的问题的时候,常常需要结合图像、文本、表格这些多种来源,不同模态的信息,进行跨模态的推理。但目前的研究工作中,很少关注于结合跨模态信息进行推理完成问答(Question Answering, QA)。因此,本文提出了一个多模态的问答数据集MMQA,其中有35.7%的问题需要利用图像、文本和表格进行跨模态推理才能正确回答;此外本文还提出了一种跨模态数据集的构建方法;随后针对这个数据集,本文提出了一个新的模型Implicit Decomp,该模型不需要对多模态问题进行显示的分解操作,而是在推理过程中隐式地对多模态问题完成分解,并进行跨模态的多跳推理。相比于单跳(One-hop)模型,本文模型在需要跨模态推理的问题上取得了比较大的提升。
数据集
如下的表格中列出了现有的三种多模态QA数据集的对比。例如,在ManyModalQA数据集中,尽管每个问题的信息都是来自于多个模态的,但是不需要跨模态推理便能完成问题回答;在HybridQA数据集中,需要利用表格和文本信息进行跨模态的多跳推理才能回答的问题,但是该数据集没有涉及到利用视觉信息,在问题类型上存在比较大的局限性。因此本文中提出了一个名为MultiModalQA的数据集,它涵盖了需要结合图像、文本和表格这三种模态完成跨模态的多跳推理才能回答的问题。
数据集样例

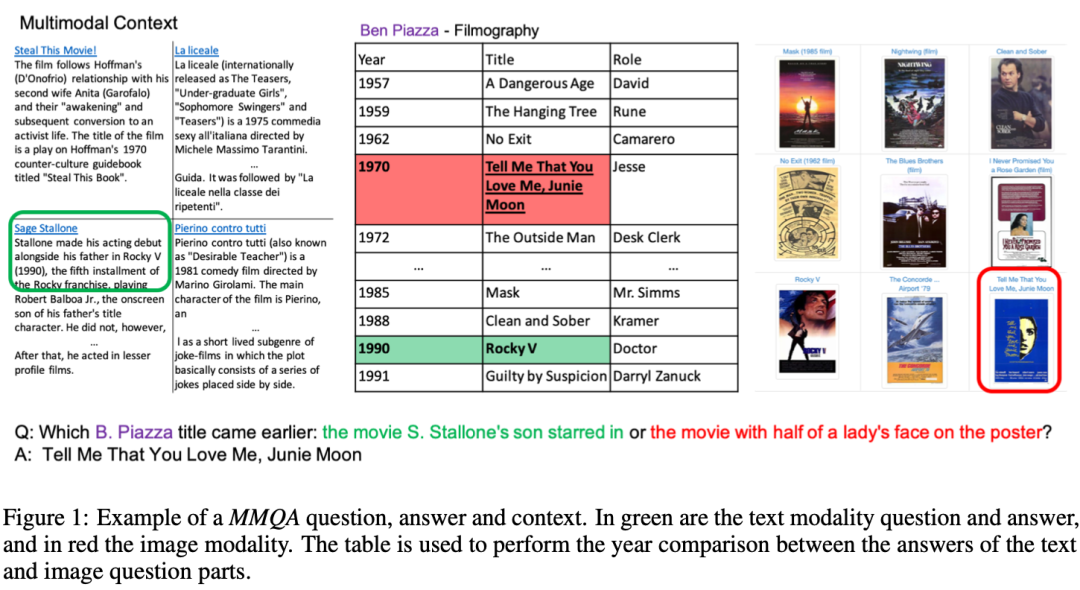
更具体来说,图中的问题可以分解为2个子问题:第一个问题是"Stallone的儿子参演的电影是哪部?",那么可以根据文本的描述"Sage Stallone和它的父亲一起出演了Rock V这部电影",然后再通过表格中的信息,得到这部片子上映在1990年。对于第二个问题"海报上有半个人脸的电影是哪一部?",同理可以根据图像和表格中的信息,推理得出这部电影上映在1970年。最后结合这两部分简单的问答结果,推理出最终的答案,即1970年上映的那个"Tell me that you love me"上映时间更早。
数据集构造过程
数据集的构造过程整体可以概括为以下3个部分:(1)背景构建(Context Construction),(2)问题生成(Question Generation)以及(3)转述润色(Paraphrasing)。
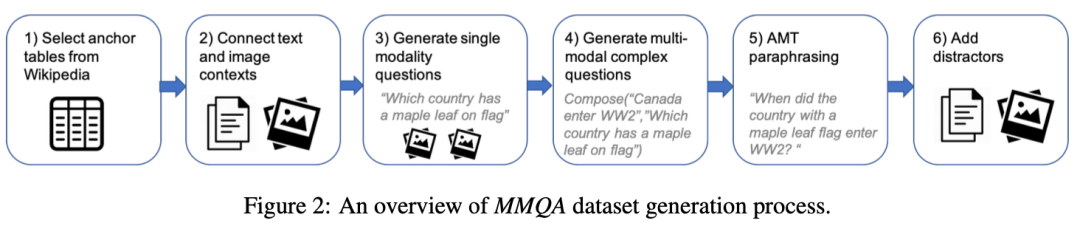
(1)背景构建是指从维基百科中提取表格,然后将每个表格和现有的阅读理解数据集中的图像和文本进行对齐。
(2)在问题生成这一步骤当中,对于不同模态的QA有不同的生成方式。例如,对于表格QA,根据刚才得到的背景信息,使用模板的形式构建的问答对。如下:
In [table title] of [Wikipedia page title] which cells in [column X] have the [value Y] in [column Z]? 对于图像QA,直接通过众包的方式进行问题生成。对于文本QA,利用现有阅读理解数据集中的问题和答案进行构造。
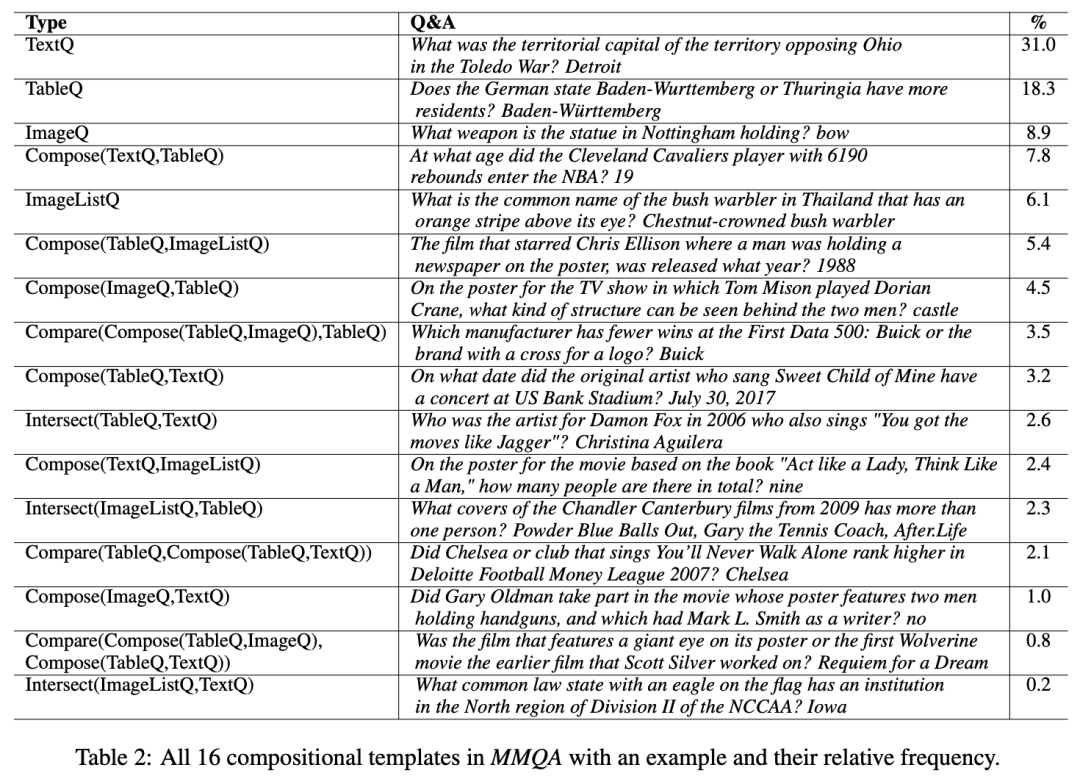
为了将单模态的问题结合起来,本文利用了多种逻辑推导的操作,总共介绍了16种问题结合的方法,如下表中所示。
这些逻辑操作其实主要由3种基本的操作组成(composition, conjunction, comparison),然后通过对不同的模态和逻辑操作进行组合,得到伪语言(pseudo-language)形式的问题。举例来说,COMPOSE操作的过程是,输入2个问题,比如分别为"Where was Barack Obama born?"和"Who was the 44th president of the USA?"。然后把第一个问题中的WikiEntity(也就是Barack Obama)替换为第二个问题,并把被替换的WikiEntity作为答案(Barack Obama)。
(3)转述润色。本文采用AMT众包的方式,对刚才自动构建的伪语言形式的问题进行润色,让语言变得更加流畅。
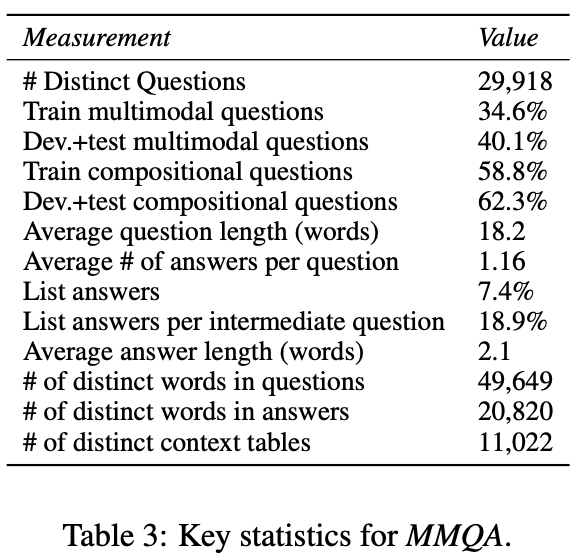
下面的表格中展示了MMQA数据集的统计结果,如问题平均长度18.2个单词,答案平均长度2.1个单词。
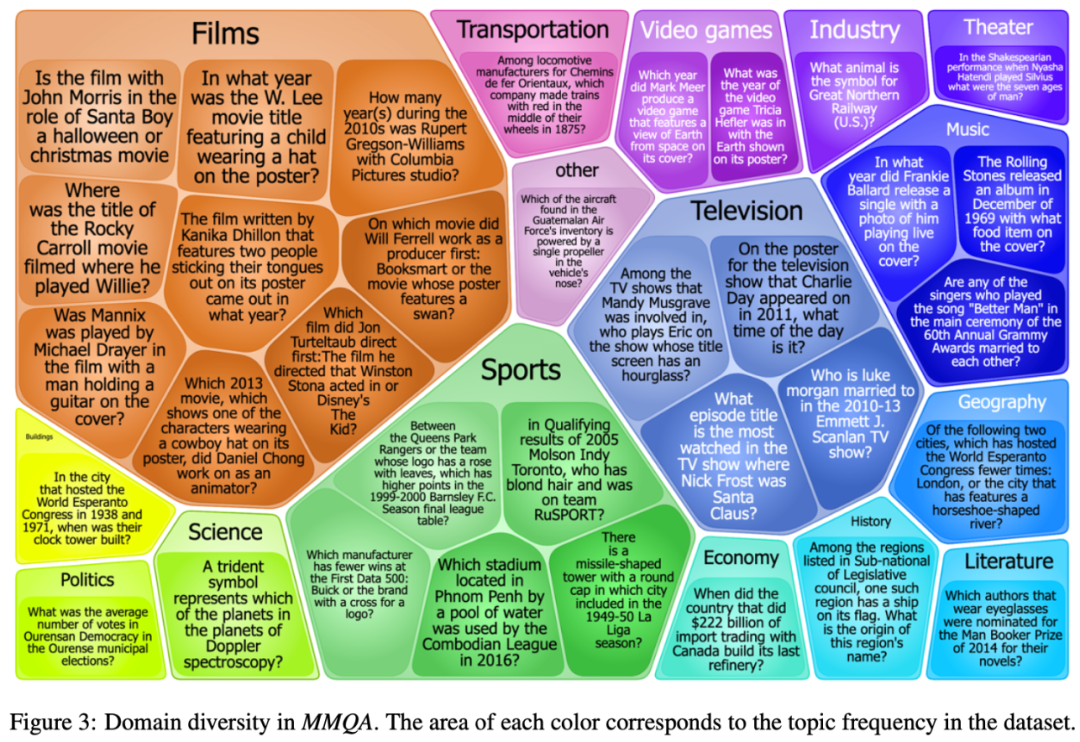
下图是MMQA数据集的多样性统计结果,可以看出数据集中的问题类型是非常丰富的,颜色区域的大小代表了所占比例的多少,如电影类的问题占了36%。
方法
为了解决MMQA问题,本文提出了一种名为Implicit Decomp(Multi-modality QA Model)的多模态QA模型。该模型主要包含2个部分,分别是3个单模态的QA模块(Single-modality QA Modules),然后通过一种多跳分解的方法(Multi-Hop Implicit Decomposition)组合不同的单模态QA模块,来进行多跳多模态推理。
单模态QA模块
Text QA模块:该模块基于RoBERTa-large,类似于用于MRC任务的预训练模型,输入问题和段落,预测答案的起始位置和终止位置。
Table QA模块:基于RoBERTa-large和2个线性分类器。该模块的输入是问题和表格,输出是选择表的部分单元格,和要施加到这些单元格上的聚合操作类型(SUM, MEAN, COUNT, YES, NO, and NONE) 。具体来说,把表格一行一行地拉平,最终拼接变成一个长文本。然后输入到预训练模型的形式为"问题 + 拉平的表格"。每个输入的token都会由1个分类器输出概率,单元格中的所有token的平均概率大于0.5的单元格会被选中。此外,还有一个线性层会输出聚合操作的类型,包括了SUM、MEAN、COUNT、YES、NO和NONE。然后把聚合操作再应用到单元格上,再输出最终该模块预测的结果,其中聚合操作类型YES和NO输出"yes"和"no","NONE"表示输出所有单元格。
Image QA模块:该模块基于VILBERT-MT,输入一个问题和一组图像,输出每个问题和图像的答案。
多跳隐式分解
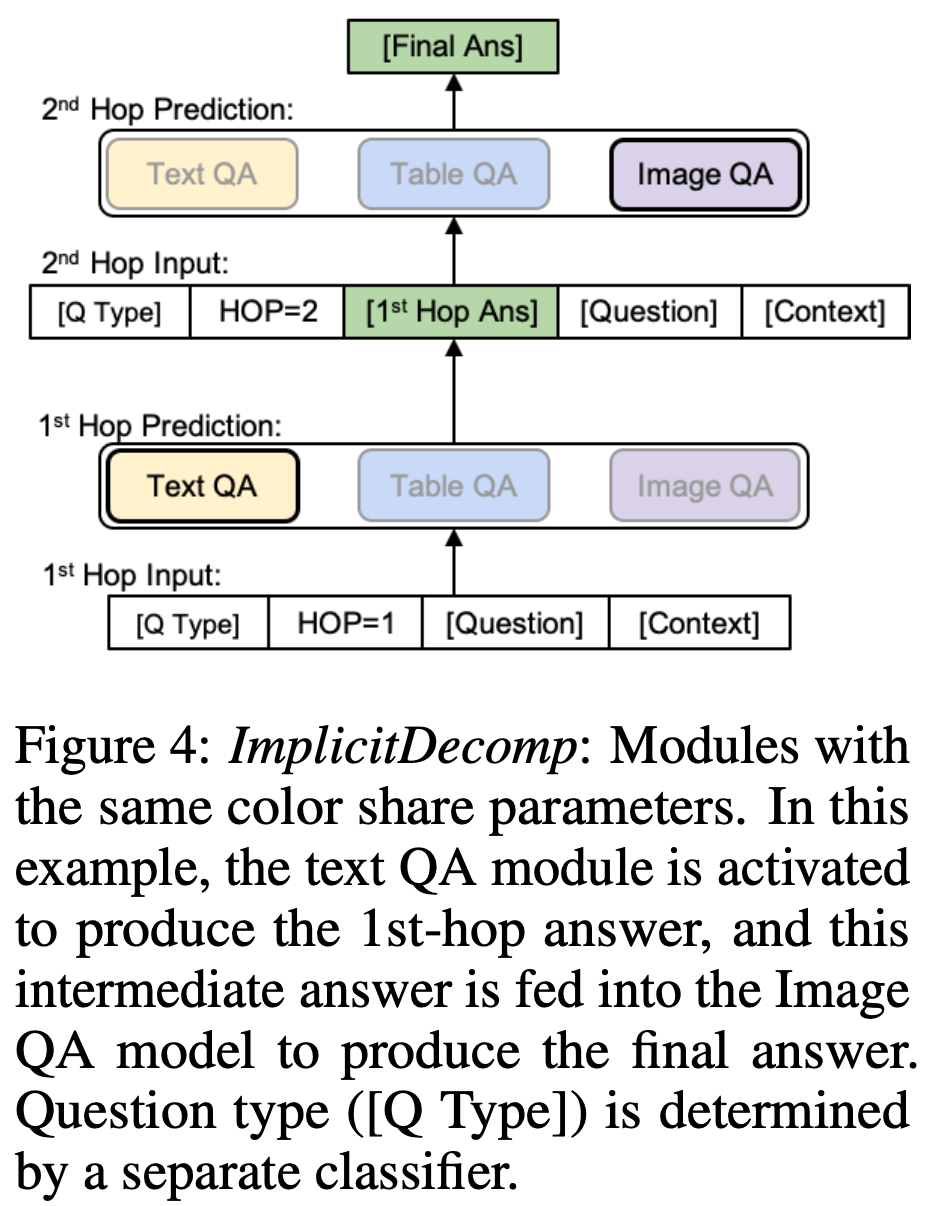
本文提出了多跳隐式分解(Multi-hop Implicit Decomposition)的方法结合上述单模态QA模块。具体来说,本文基于RoBERTa-large训练了一个问题种类分类器(Question-type Classifier)。在推理的最初阶段,先通过问题种类分类器,预测问题类型。问题类型包含了指定激活哪些模态的模块,以及推理的逻辑顺序。文本中的多跳限制为最多2跳。
下图展示了本文方法的示意图。(1)在最开始的推理阶段,首先得到问题类型(Q Type),然后将现在处于第几跳(HOP),问题(Question)和上下文(Context)拼接起来,输入到模型当中。例如,第一跳现在激活的是Text QA模块,然后得到通过该模块预测的答案;(2)第二跳的输入利用了上一跳的问答信息。比如将刚才第一跳输出的结果也拼接到输入中,输入给第二跳的模型。通过这种方法,第二跳的模型便可以实现跨模态的推理;(3)然后将该模块的输出作为最终的预测。在训练阶段,由于数据集中已经提供了丰富的监督信号,所以整个模型通过有监督的方法进行训练优化。
实验结果
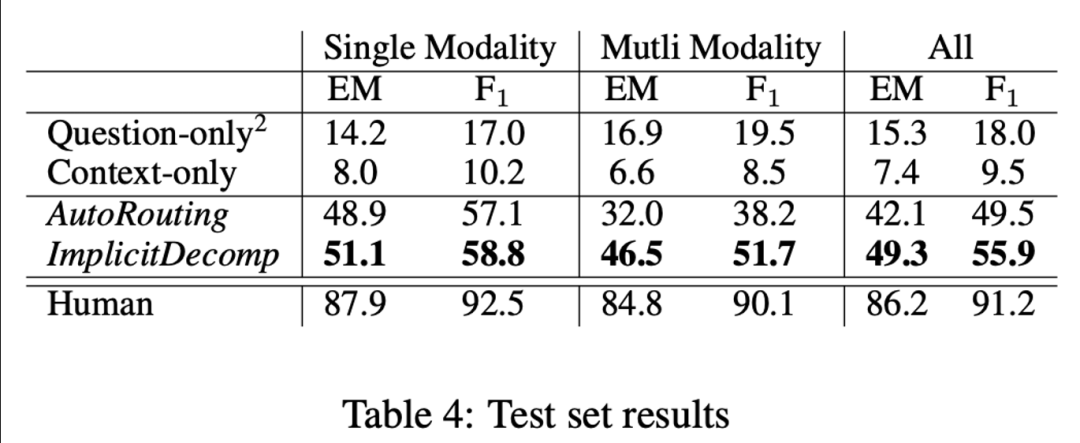
本文在不同的设定下进行了实验,包括了:(1)单模态的问题(Single Modality),需要多模态推理回答的问题(Multi Modality)和所有问题(All)。评价指标采用了EM和F1。在测试集上的结果如下表所示,从中观察发现,本文提出的ImplicitDecomp模型取得了非常大的提升。但是和人类相比仍有较大的差距,还存在着较大的提升空间和较多可以进一步探索的方向。
此外,为了说明ImplicitDecomp模型确实能够进行推理,回答跨模态问题。本文进行了进一步的分析,结果如下表所示。从该表中可以发现,当第一跳答案正确时,F1可以取得较高的分数,比如61.1;但是当第一跳预测错误时,F1仅能取得50多。这在一定程度上可以说明第二跳依赖于第一跳的结果,模型的预测准确率确实受到了多跳推理的影响。


总结

此次 Fudan DISC 解读的三篇论文均和多模态学习相关,主要介绍了多模态领域中的一些新的任务、方法以及应用。为了实现更全面、更综合的理解,利用多模态学习是非常重要的。而且多模态学习仍然处于快速发展的阶段,应用场景更为多样,技术更为复杂,同时也越来越贴合实际。在最近的研究工作中,引入自监督的方法(如对比学习),以及引入跨模态的推理,是当前多模态学习相关工作的研究热点。
供稿丨王瑞泽 编辑丨邹瑞祥 责编丨李志伟供稿人:王瑞泽丨研究生三年级丨研究方向:多模态文本生成、知识融入丨邮箱:zwang18@fudan.edu.cn
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦