日志分析,数据统计,命令结果过滤。。。等等情况下,awk绝对是运维人的好帮手,它能让你在庞大而又有规律的数据中过滤、统计出你想要的数据,熟练运用awk,你的工作效率一定会有很大的提升
")
awk [-F分隔符] [-v 变量=值] ‘BEGIN { 初始化 } { 循环执行部分 } END { 结束处理 }’ file1 file2 ···
1.1.1·参数
-F:指定分割符,默认空格(如 -F"," 以逗号分割)
-v:定义一个变量,如 last -n 2 | awk -v a=1 '{print a}'
1.1.2·变量
$0:当前读取的整行数据
$1~$n:按照分割符分割之后第一列数据,第二列等依次类推
NF:每行被分割之后的字段数量
NR:awk读取的行数
FNR:当前读取的记录数,不同于NR,因为当awk读取第二个文件的时候,FNR就会从0开始,但是NR会继续递增
RS:输入文件的行分隔符,缺省是换行符
FS:分割字符 默认是空格和TAB
END:读完所有数据后执行
BEGIN:在读取数据之前执行
想过去最近两条登陆信息 只需要把用户和IP打印出来,且只打印root用户的信息

可以这样执行:last -n 2 | awk '$1=="root"{print $1 "-" $3}'
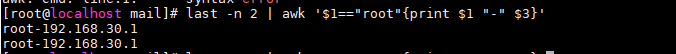
命令的整个处理流程如下:
1.读入第一行,并将第一行的数据填入$0,$1,$2等变量中
2.依据条件类型的限制,判断是否需要进行后面的动作
3.做完所有的动作与条件类型
4.若还有后续的行,重复以上动作,直到所有数据读取完毕
awk 'BEGIN{ print "运行前" }{ print "运行中" }END{ print "运行后" }'
也可以放在sh脚本文件中:
1.4.1·三元运算符(表达式?动作1:动作2)
awk 'BEGIN{a=2;print a==1?"ok":"no ok";}'
![]()
1.4.2·字符串函数操作
gsub(全局替换):
gsub("旧", "新", $0)【将当前行所有的"旧"替换成"新"】
sub(一次替换,替换第一次匹配的):
sub("旧", "新", $0)【将当前行第一个"旧"替换成"新"】
substr(截取字符串):
substr($0, 1, 5)【截取当前行行下标为1开始,长度为5的字符串(下标从1开始)】
index(匹配查找子字符串):
index(str, subs)【判断str字符串张是否包含subs字符串,如果包含,返回subs的下标位置(下标从1开始计算)。如果不包含,则返回0】
length(字符串长度):
length(str)【返回字符串长度】
tolower(将字符串都变为小写):
tolower(str)
toupper(将字符串都变为大写):
toupper(str)
split(分割字符串,保存为数组):
split(str, arr, ",")【将str用,分割,保存成属组arr】
a.acc日志格式如下:
100.120.239.186 - - [15/Mar/2020:11:12:40 +0800] "HEAD / HTTP/1.0" 200 273 "-" "-"
2.1.1·统计各个IP的访问量,并排序
awk '{a[$1]++}END{for(i in a) print i,a[i] }' a.acc | sort -n -r -k

2.1.2·统计200状态的各个IP的访问量,并排序
awk '$9==200{a[$1]++}END{for(i in a) print i,a[i] }' a.acc | sort -n -r -k 2

2.1.3·统计5-10行区间内 各个IP的访问量,并排序
awk '{if(NR>=5&&NR<=10)a[$1]++}END{for(i in a)print i,a[i]}' a.acc | sort -n -r -k 2

访问日志还有很多中情况的分析可以用到awk,例如找分析指定时间段内的访问情况,指定接口的访问情况等等
2.2.1·查看当前目录各个用户的文件数量
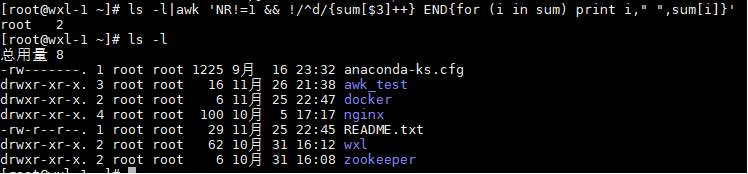
ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s ",i," ",sum[i]}'
(!/^d/剔除了以d开头的行,也就是不计算目录)